
Design, Model & Explore Approximate Arithmetic Circuits: A Tutorial
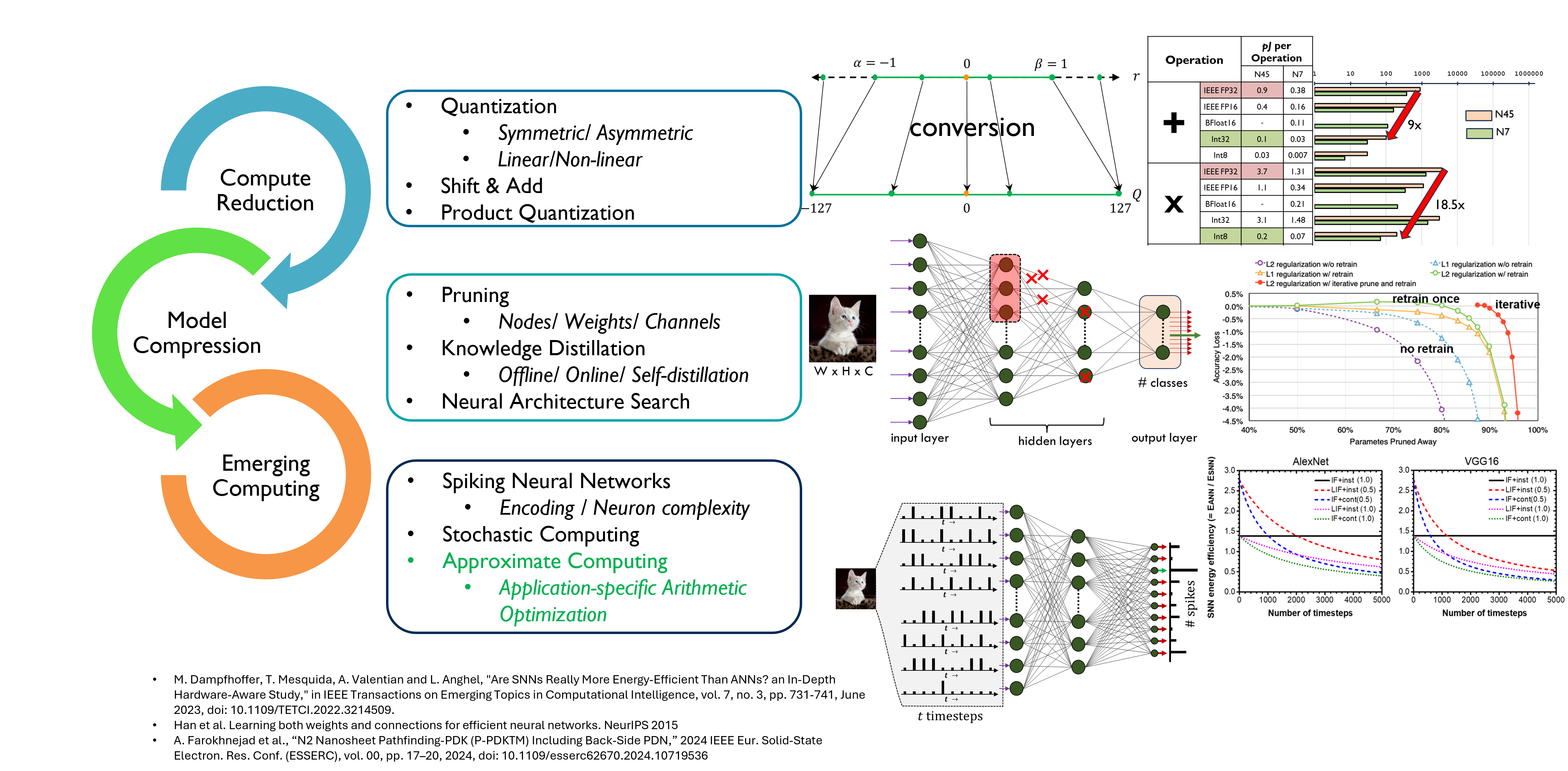
Edge AI lives under tight energy, memory, and latency budgets; practitioners therefore mix several levers—precision scaling/quantization, pruning with retraining, and even event-driven SNN formulations or stochastic techniques—to bend the cost–accuracy curve (Figure 1). In this tutorial we add one more lever to that toolkit and make it the centerpiece: Approximate Computing (AxC), specifically application-specific approximate arithmetic. Rather than treating approximation as a blunt reduction in fidelity, we’ll show how to design operator variants, model their PPA/behavior trade-offs, and explore them systematically so they complement (not replace) the other methods you already use on the edge.
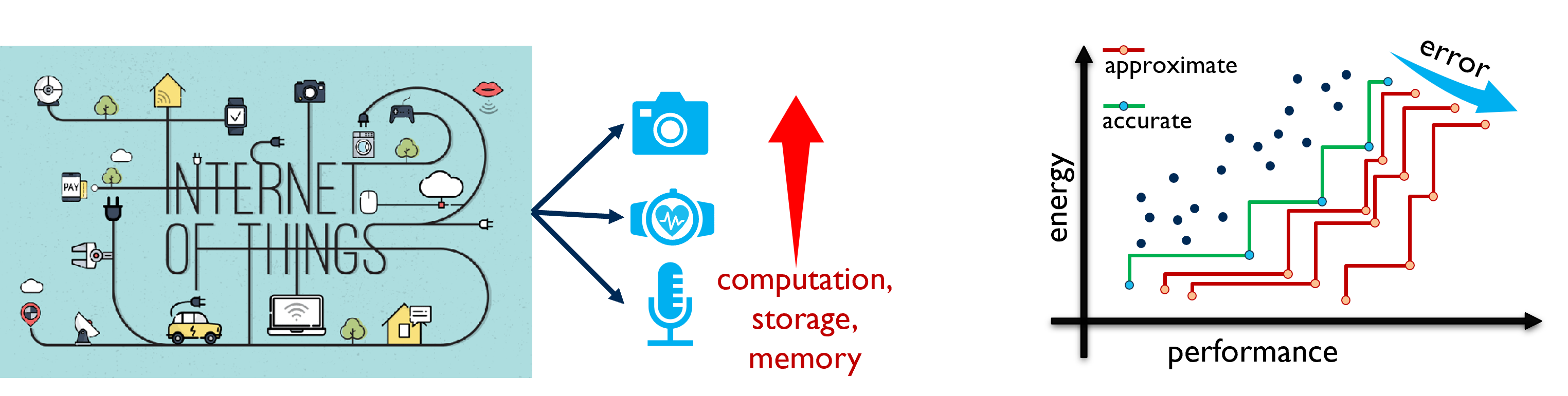
As sensing at the edge explodes (vision, biomedical, audio), the dominant costs shift to computation, storage, and memory, tightening energy and latency budgets. Figure 2 frames AxC as an orthogonal dimension to the usual levers: instead of only moving along a fixed cost–accuracy staircase (bit-width changes, sparsity, etc.), AxC shifts the whole staircase—creating new Pareto steps that reach further into the high-efficiency region for the same or better task accuracy. This tutorial focuses on making that shift systematic through application-specific approximate arithmetic.
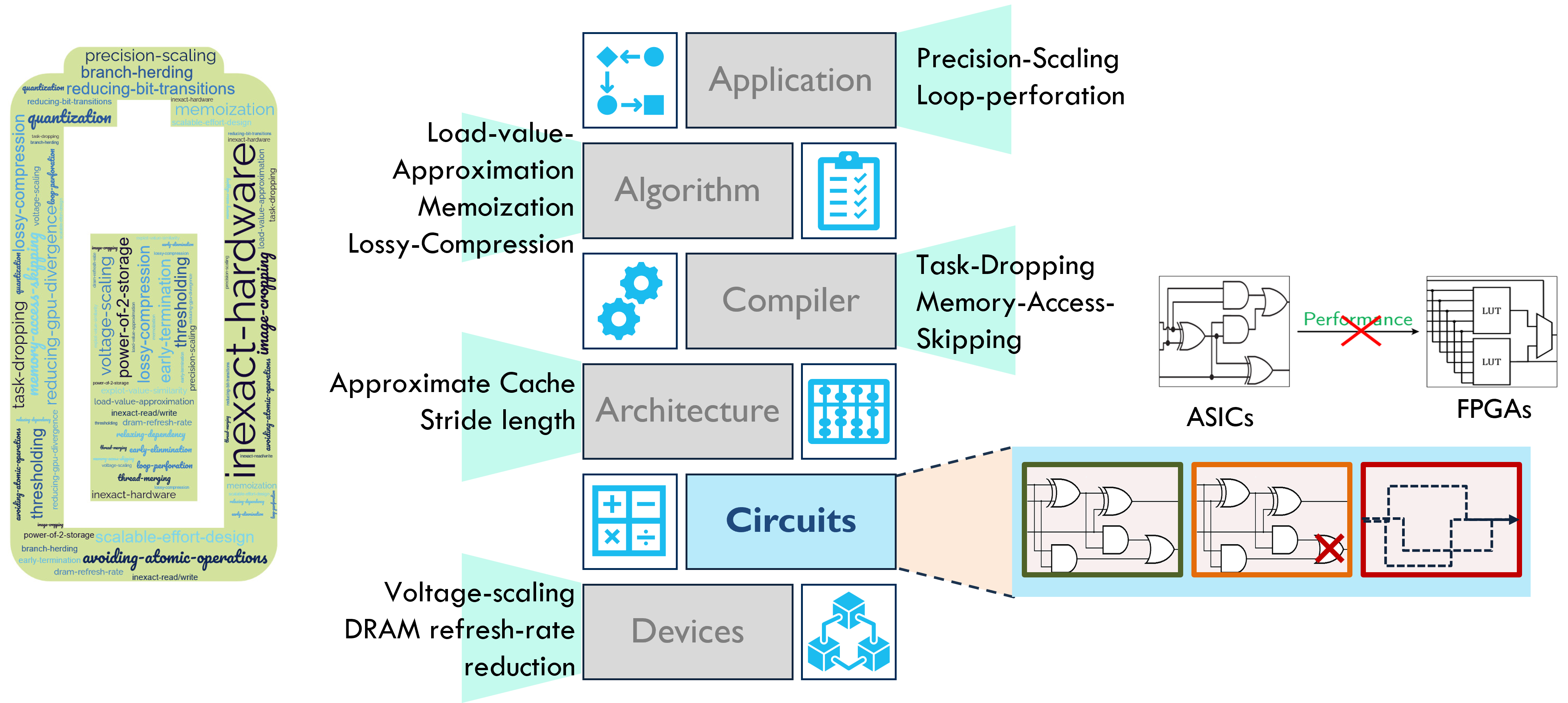
Approximation opportunities exist from Application and Algorithm down through Compiler and Architecture, but this tutorial narrows to the Circuits / operator layer—where we can explicitly shape adders, multipliers, and MACs for task-tolerant error (Figure 3). A key message here is fabric awareness: designs tuned for ASIC standard cells rarely translate 1-to-1 onto LUT-based FPGAs; gate-level wins can disappear after technology mapping. We therefore treat approximate arithmetic as fabric-conscious from the start—choosing and evaluating operator variants that co-optimize for the target fabric (FPGA vs. ASIC), rather than assuming portability of PPA advantages.
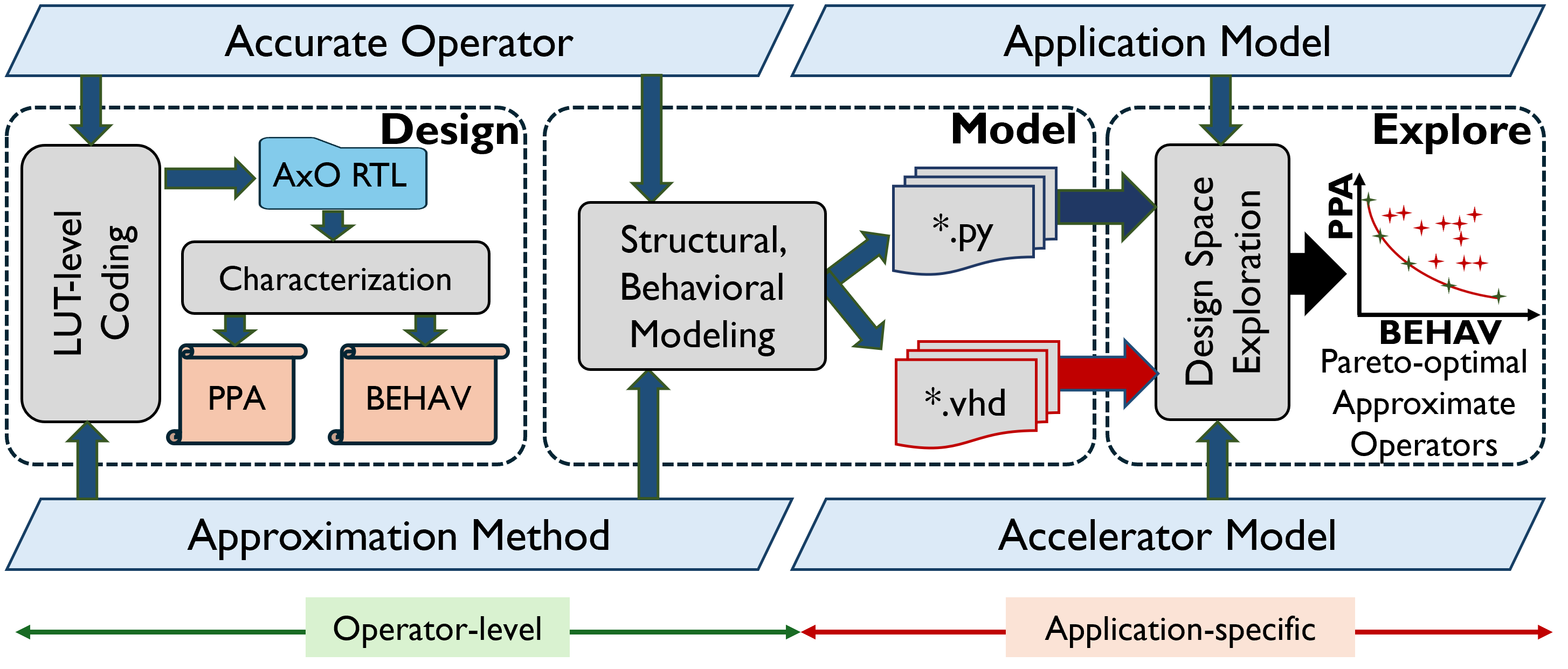
Bringing the narrative together, Figure 4 is the roadmap we’ll follow. We start from accurate operators and design approximate variants in a fabric-aware way, then characterize them for PPA and BEHAV. We model these operators consistently at both software (Python) and HDL (VHDL) so application simulators and hardware agree. Finally, we explore the space with multi-objective DSE to surface Pareto-optimal operators tailored to the application model. The tutorial is structured around these three phases—Design → Model → Explore—so you can reproduce the pipeline end-to-end and adapt it to your workload.
Start with the Tutorials.
Tutorial Materials at https://gitlab.com/ssatyendras_public/tools/axosyn.git under the `tutorials/` directory
For any queries, please contact Salim Ullah.
Related Publications
-
Salim Ullah, Siva Satyendra Sahoo, Nemath Ahmed, Debabrata Chaudhury, and Akash Kumar. 2022. AppAxO: Designing Application-specific Approximate Operators for FPGA-based Embedded Systems. ACM Transactions Embedded Computing Systems (2022). https://doi.org/10.1145/3513262
-
Salim Ullah, Hendrik Schmidl, Siva Satyendra Sahoo, Semeen Rehman, and Akash Kumar. 2019. Area-Optimized Accurate and Approximate Softcore Signed Multiplier Architectures. IEEE Transactions on Computers 70, 3 (2019), 384–392. https://doi.org/10.1109/TC.2020.2988404
-
Salim Ullah, Siva Satyendra Sahoo, and Akash Kumar. 2023. CoOAx: Correlation-aware Synthesis of FPGA-based Approximate Operators. GLSVLSI 2023. https://doi.org/10.1145/3583781.3590222
-
S. Ullah, S. S. Sahoo and A. Kumar, 2024. Enabling Energy-efficient AI Computing: Leveraging Application-specific Approximations (Education Class). CASES 2024, pp. 3–4. https://doi.org/10.1109/CASES60062.2024.00014
v1.0 @ ESWeek 2025, Taipei, Taiwan

